This project is a comprehensive text analysis pipeline developed in Python. It extracts content from a list of URLs, performs various text analyses, and generates insightful metrics.
Key Features
- Web scraping from multiple URLs
- Sentiment analysis
- Readability metrics calculation
- Error handling for 404 pages
Components
1. Extraction Module (extraction.py)
- Reads URLs from an Excel file
- Extracts text content from web pages
- Handles 404 errors and generates an error log
- Saves extracted text to individual files
2. Analysis Module (analysis.py)
- Processes the extracted text files
- Performs sentiment analysis using TextBlob
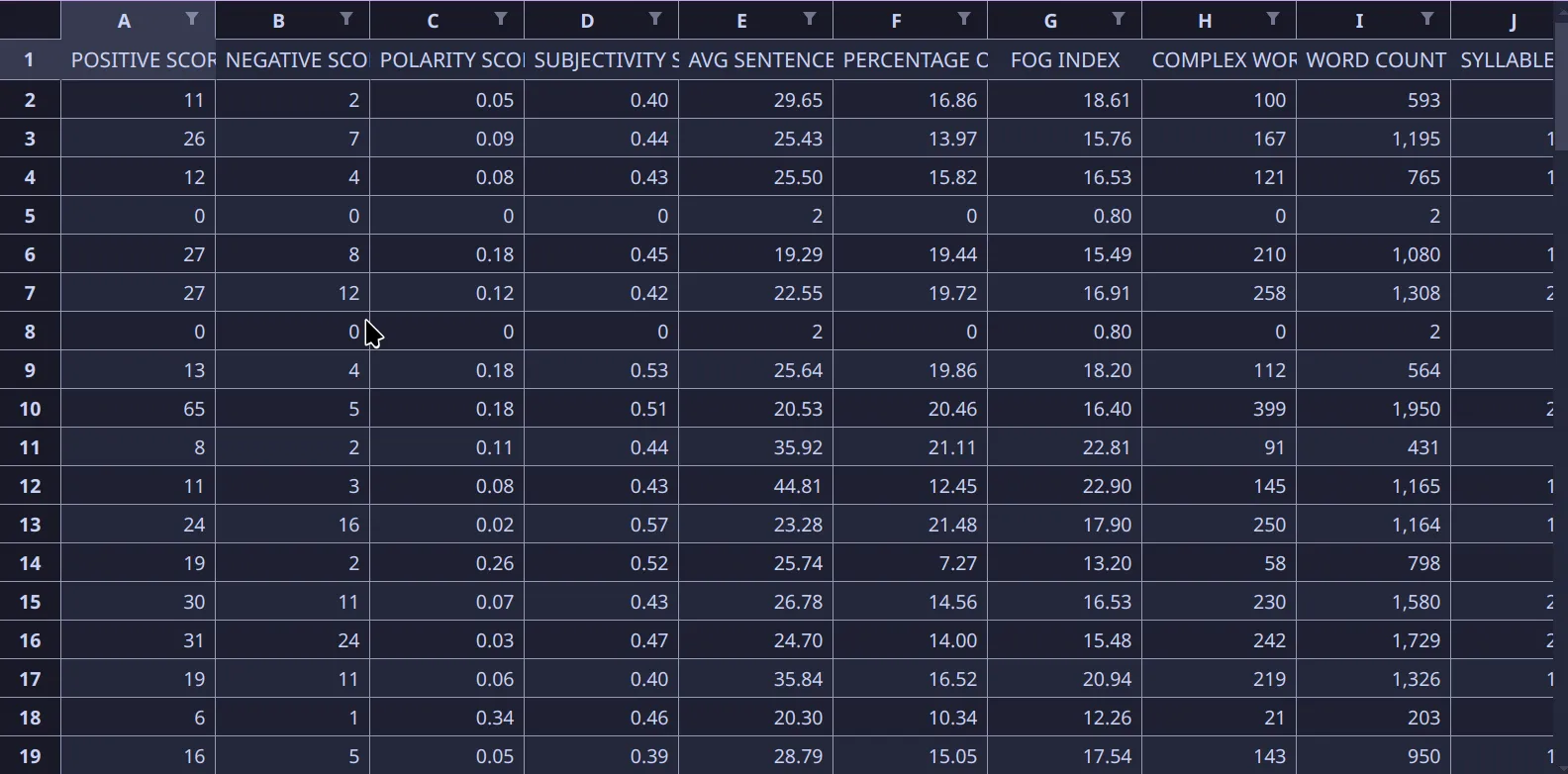
- Calculates various readability metrics:
- Positive/Negative scores
- Polarity and Subjectivity scores
- FOG index
- Complex word count
- Syllable count
- Personal pronouns count
- Generates an Excel file with comprehensive metrics
Tech Stack
- Python
- Pandas for data manipulation
- BeautifulSoup for web scraping
- TextBlob for sentiment analysis
- NLTK for natural language processing tasks
This project demonstrates my proficiency in web scraping, text processing, and data analysis, providing valuable insights from web content.